*본 블로그는 내가 가진 지식을 누군가에게 공유하기 위함이라기 보다는, 현재 파이썬을 학습하는 입장에서 새롭게 배운 내용을 재정리함으로써, 스스로의 학습효과를 올리기 위함임을 밝힙니다.
*그럼에도 불구하고 계속해서 본 글을 읽고 계신분이 계시다면, 본 블로그/기록물의 내용이 전문적인 해석과 자료(스크린샷) 보다는, 실수했던 부분, 주의해야할 부분 등에 대한 내용을 다수 포함하고 있는 점을 양해해 주시기 바랍니다.
목표: 지니뮤직에 있는 음악순위 중 50위 안에 오른 음악의 “가수”, “노래제목”, “순위”를 스크립해 온다. (크롤링과 유사한 스크립팅, 이하: 스크립팅으로 칭함)
결과물

개발환경: pycharm
언어: 파이썬: python
- 스크립팅을 실행하기 위해 파이썬 패키지 (일명: 라이브러리 또는 Requestor, Parser 등으로 불림 ), 이름이 많으므로 ‘위키피디아‘에 기입된 이름으로 사용하겠습니다. (개념은 기존 라이브러리와 유사하네요.)
Beautiful Soup is a Python package for parsing HTML and XML documents (including having malformed markup, i.e. non-closed tags, so named after tag soup). It creates a parse tree for parsed pages that can be used to extract data from HTML,[2] which is useful for web scraping.[1]
Beautiful Soup was started by Leonard Richardson, who continues to contribute to the project,[3] and is additionally supported by Tidelift, a paid subscription to open-source maintenance.[4]
It is available for Python 2.7 and Python 3.
어려운말 빼고 쉽게 풀면, Beautiful Soup는 파이썬2.7 또는 3에서 동작하며 HTML로 구성된 웹페이지를 스크립팅할때 사용하는 파이썬 패키지이다.
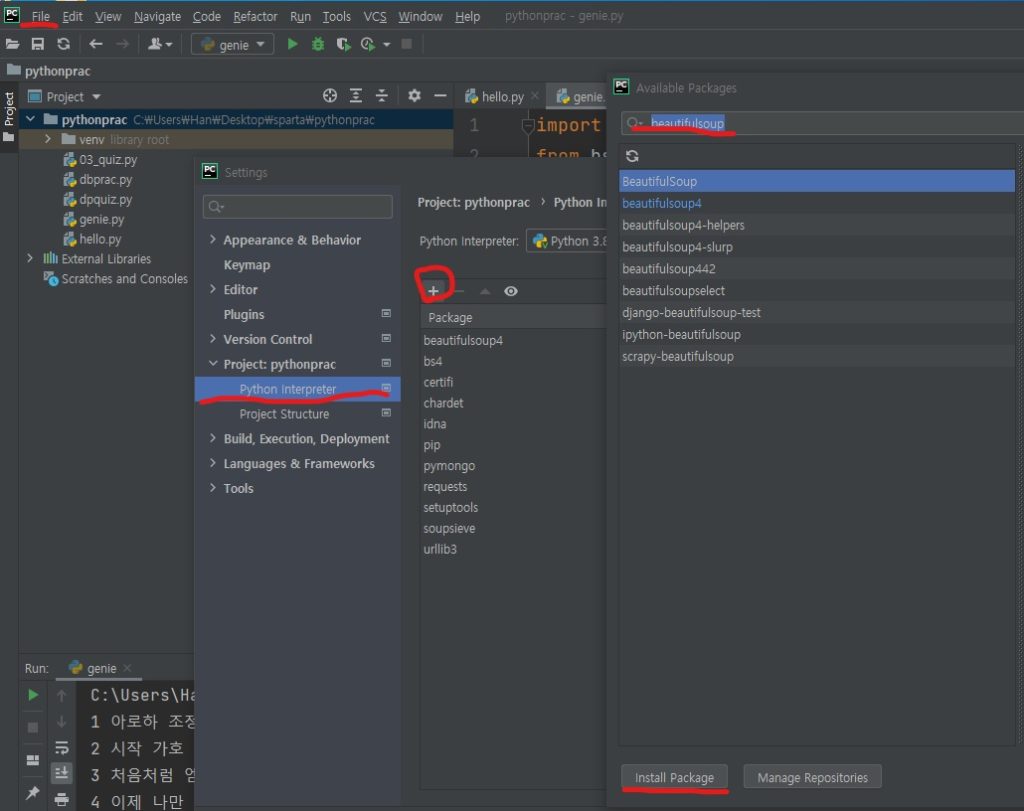
설치방법: File > Settings > Python Interpreter > “+” > 검색창 BeautifulSoup 입력 > 하단의 install 클릭
*스샷에 File을 눌렀을때 보이는 ” Settings” 이 포함되어 있지 않음.
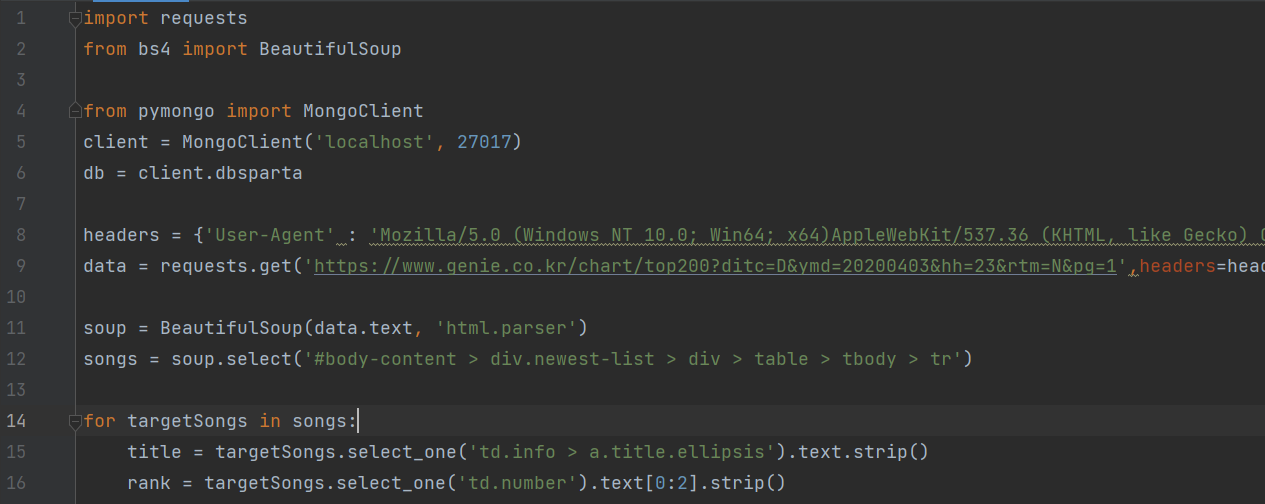
2. 새파일을 만들고 상단에 설치된 패키지를 인포트합니다.
import requests from bs4 import BeautifulSoup
3. 편의상 기본설정값을 불러와서 진행하겠습니다.
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=D&ymd=20200403&hh=23&rtm=N&pg=1',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
4. 타겟페이지(지니뮤지)에서 가져오려는 값의 셀렉터를 복사해옵니다.
예)tr값을 가져오는 경우, 앞머리부분에서 마우스 우클릭 > copy > copy selector 후 아래 소스에 붙혀줍니다.
songs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
이 값은 songs라는 변수에 리스트 형태로 저장됩니다. 이때, 값이 잘 들어오는지 중간 중간에 확인해줘야, 에러가 발생하거나 빈값이 올때 바로 수정이 가능합니다. 예)print(songs);
5. 반복문을 이용해서, 배열에 들어있는 값중 원하는 값을 불러옵니다.
for targetSongs in songs:
6. 변수 “title”에 제목을 저장하는 경우 > 페이지방문 > 제목에서 우클릭 후 ‘검사’ 클릭 > 태그 앞머리에서 우클릭 > copy > copy selector

내껀 위 화면에서 보이는것 보다 엄청 더 길다. 하는 분들은 아마 아래와 같은 값일겁니다. 이미 위4번에서 tr까지의 값은 불러와서 songs 저장되어 있으므로, tr까지의 값은 지우고, td이후의 값만 사용합니다.
body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.title.ellipsis
7. .text.strip()의 정체는?
우선, .text.strip()를 떼고 title을 화면에 출력해보면, 제목이 text로 입력되 있는것을 알수 있습니다. 또, 제목 앞뒤로 공백이 많이 포함되어 있는것도 보입니다.
text값을 불러와서 공백을 제거해주세요. 라는 의미를 담고 있습니다. 공백제거함수: .strip()

랭크와 가수 역시 같은 방법으로 불러왔습니다.
여기서, 랭크뒤에 보이는 [0:2]는 불러온 text값이 여러개인 경우, 0번부터 2번까지의 데이터를 사용하고 그외는 제거하는 의미를 담고 있습니다. 케바케이므로, 값이 제대로 불려오는지를 확인하면서 2의 값을 5 또는 10으로 변경해주는게 좋습니다.

스크립팅을 하면서 가장 애먹은 부분은 7번, 해당 태그열을 가져온 후, 필요한 값을 추출하는 과정이였습니다.
아직 3번정도밖에 안해본터라 기존에 작업된 내용을 확인해가며, 진행했네요.
글을 읽으면서 이미 아시는 분들도 계시겠지만, 저는 “스파르타코딩클럽”을 통해서 코딩을 다시 공부하고 있습니다.
저도 오래전에 IT학과를 졸업했고, 개발을 언어를 배워본 경험자로써, “스파르타코딩클럽”의 강의에 대한 느낌을
짧게나마 적어보자면. 제가 지난 15년간 보아온 각종 인강중에서는 최고임을 인정합니다.
초보자분들의 경우, 속도가 빠르다, 설명이 부족하다, 등을 느끼시는 분들도 계실꺼고, 때문에 이해가 잘되지 않는다는 분들도 분명히 계실껍니다. 근데 그건, 강의 내용이 부족한게 아니라, 지금 배우고 계신 내용 (코딩, 개발) 분야가 원래 배우기 어렵습니다.
말을 느리게 한다고해서 이해가 잘되는게 아니며, 같은 말을 여러번 하는것 역시, 강의 시간만 길게합니다.
이해가 안되시는 부분은 반복 재생이 답이고, 이해가 바로바로 되는 분들은 빠르게 다음 과정으로 넘기시면 될것 같네요.
이게 참, 쓰다보니, 의뢰 받고 광고로 쓰는 글처럼 보여지는,
제가 그런 의뢰를 받을만한 블로거나 유튜버도 아니니. ㅋㅋㅋ 다들 아시죠?
전 그냥 제가 요즘 빠져있는거에 대해 감상문을 찌끄린정도라는거. ㅋ
제가 이 글에 “스파르타코딩클럽”의 태그를 다는 이유는, 제게 좋은걸 가르쳐주는 선생님에 대해 예의? 정도라고 해두죠. 스승에 날도 가까워오는데. ㅋ
그럼 좋은 하루 되시고, 새로운 내용으로 또 오겠습니다.
#스파르타코딩클럽 #크롤링 #웹스크립팅 #BeautifulSoup #HTML parser